Zoals een schatzoeker in het veld gebaat is bij een goede metaaldetector, zo heeft ook de data analist gereedschap nodig. Ik schreef hier al een keer over de programmeertaal Python, voor mij een nieuwe verworvenheid. Inmiddels heb ik zowel professioneel als hobbymatig vlieguren opgedaan in Python zodat ik u deelgenoot kan maken van mijn aanpak. Vandaag begin ik eenvoudig en actueel door een plaatje te maken van de waterstanden en afvoeren in de Rijn van dit moment.
Databronnen
In 1992 liep ik stage bij Rijkswaterstaat bij een afdeling met veel kennis van de kustwateren, metingen en modellen. Het was zes jaar na de oplevering van de Stormvloedkering Oosterschelde en veel collega’s hadden daar jaren aan meegewerkt. Als jonge hond voelde het alsof ik de boot had gemist.
Bij de Deltawerken was veel data verworven en vastgelegd. De vastlegging was divers; veel stond nog op papier. Maar her en der waren schoenendozen met stapels ponskaarten te vinden. Groot was de frustratie als de trouwe bewaarder zijn zorgvuldig gebundelde en gemarkeerde kaartjes in een ongeordende en onherkenbare berg aantrof. Want elastiekjes bleken na verloop van tijd vanzelf stuk te gaan en notities in potlood worden geleidelijk onleesbaar. De bergen ongemarkeerde ponskaarten waren één van de gespreksonderwerpen aan de lunchtafel. Speculatie wat erop zou staan. En natuurlijk de vraag of het de moeite loonde om die data nog te redden.
Eerlijk gezegd weet ik niet wat er van de ponskaarten geworden is. Dat weet ik wel van hele grote stapels vergeelde rapporten met eindeloze cijferreeksen. Die zijn door een data-typist (is dat nog een beroep?) allemaal ingeklopt. De dienstplicht bestond nog, inclusief het fenomeen van de vervangende dienstplicht voor gewetens-bezwaarden. Op een dag verscheen er een jongeman (leeftijdgenoot) met een typesnelheid en hyperconcentratie die ik daarna nooit meer heb gezien. Binnen enkele dagen lag zijn kamer vol met stapels vergeelde rapporten. Telkens nam hij er één mee naar de terminalruimte (die was er nog, we hadden een Unix-aangedreven Mainframe) en ramde hij in een noodvaart het rapport in de computer.
Ik denk nog weleens terug aan hem, vooral als ik de prachtige site waterinfo.rws.nl raadpleeg. Voor iedereen die dat wil is een enorme hoeveelheid data uit de Rijkswateren nu met een paar muisklikken te verkrijgen. De data gaat terug tot 1900. Wie meer wil (zoals ik, vaak) wordt vriendelijk geholpen door de data-afdeling van Rijkswaterstaat. Kenmerkend was het vriendelijke bericht dat ik ooit van ze ontving: "Beste heer Voortman, Dank voor uw vraag. Wij hebben u echter alles gegeven wat wij in huis hebben. Met vriendelijke groet, ....". Het beschikbaar maken en houden van die data is naar mijn mening een hele nuttige investering.
Ook het KNMI beschikt over veel data en ook die is prachtig ontsloten. U kunt het weer van uw voorouders raadplegen, want ook bij het KNMI kunt u terug tot 1900, in ieder geval voor het gemiddelde weer per dag. Waarnemingen per uur zijn er vanaf 1950.
Als laatste noem ik de KNMI Climate Explorer. Een enorme verzameling van klimaatgerelateerde data. Waarnemingen, modelresultaten. Alles waar de datajunk van droomt. Veel minder geordend want voor zover ik het begrijp kunnen onderzoekers zelf hun datareeksen uploaden. Rondsurfend op die site voel ik me een kind in een snoepwinkel.
Data oogsten
Wie dus iets wil leren over het Nederlandse watersysteem of over het klimaat hoeft slechts achter de computer plaats te nemen en de data ligt onder handbereik. Tot voor kort betekende dat grote lappen data downloaden (klachten van de kinderen omdat de game vastloopt....), vervolgens die data proberen te lezen, constateren dat het te groot is voor Excel.... Kortom, veel gepruts met veel te grote lappen data voordat je met het echte werk kan beginnen.
Voor sommige datasets zal dat de werkwijze blijven. Professioneel ontsloten data, zoals van het KNMI en Rijkswaterstaat, is echter ook vanuit scriptjes te benaderen. Moderne programmeertalen, zoals Python, bieden de mogelijkheid om rechtstreeks met websites te communiceren. De instructies daarvoor zijn bij Rijkswaterstaat en bij het KNMI keurig beschikbaar voor de enthousiaste hobbyist. Maar als relatieve “Newbie” in Python toch nog lastig en tijdrovend om te implementeren.
In “Mens en Machine” beschreef ik Python als een product van de “hacker”- gemeenschap. En dat houdt in dat alles wat ik verzin vaak al door iemand is uitgewerkt en beschikbaar gemaakt op Internet. Soms zelfs meerdere malen. Voor KNMI data heb ik twee zogenoemde “Packages” kunnen vinden en voor RWS data één. Met KNMI-data wil ik later nog aan de slag, maar voor de mede-junks onder u: na testen van beide packages geef ik de voorkeur aan de package "knmy".
Voor de demo van vandaag ga ik naar Rijkswaterstaat-data kijken. Daarvoor gebruik ik het package ddlpy. Gemaakt en beschikbaar gesteld door “SiggyF” op Github. Github is de “rommelmarkt" waar je al deze zelfgemaakte spullen vindt. En net als een echte rommelmarkt is het inderdaad een mix van pure troep, half-werkend spul en echte juweeltjes.
Met het package van Siggy gekoppeld aan mijn eigen code praat mijn script rechtstreeks met Rijkswaterstaat. Ik ben dus ontslagen van het tijdrovende downloaden en verwerken van grote bestanden. Nadeel is dat je telkens de data “vers” download wat tijd kost (en leidt tot klachten van gamende tieners). Het kan daarom nog steeds handig zijn om je eigen datahuis op te bouwen. Daar zal ik in een vervolg-blog over schrijven; ten minste, als ik het niet vergeet…..
Plaatjes kijken - Lobith
De eerste vaardigheid die de data-analist moet opdoen is plaatjes maken. En dat is ook wat ik vandaag laat zien. Er is niets beter dan plaatjes kijken om gevoel te krijgen voor je data.
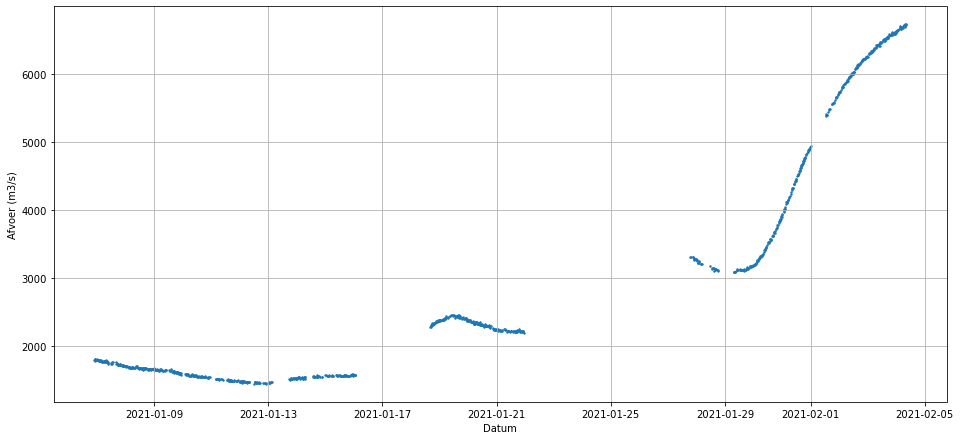
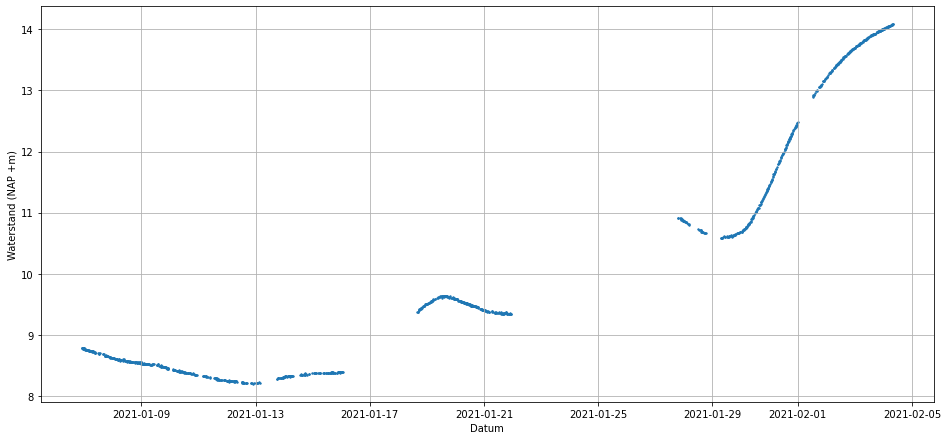
Momenteel voeren Rijn en Maas veel water af. Ik laat de Python daarom los op Lobith.
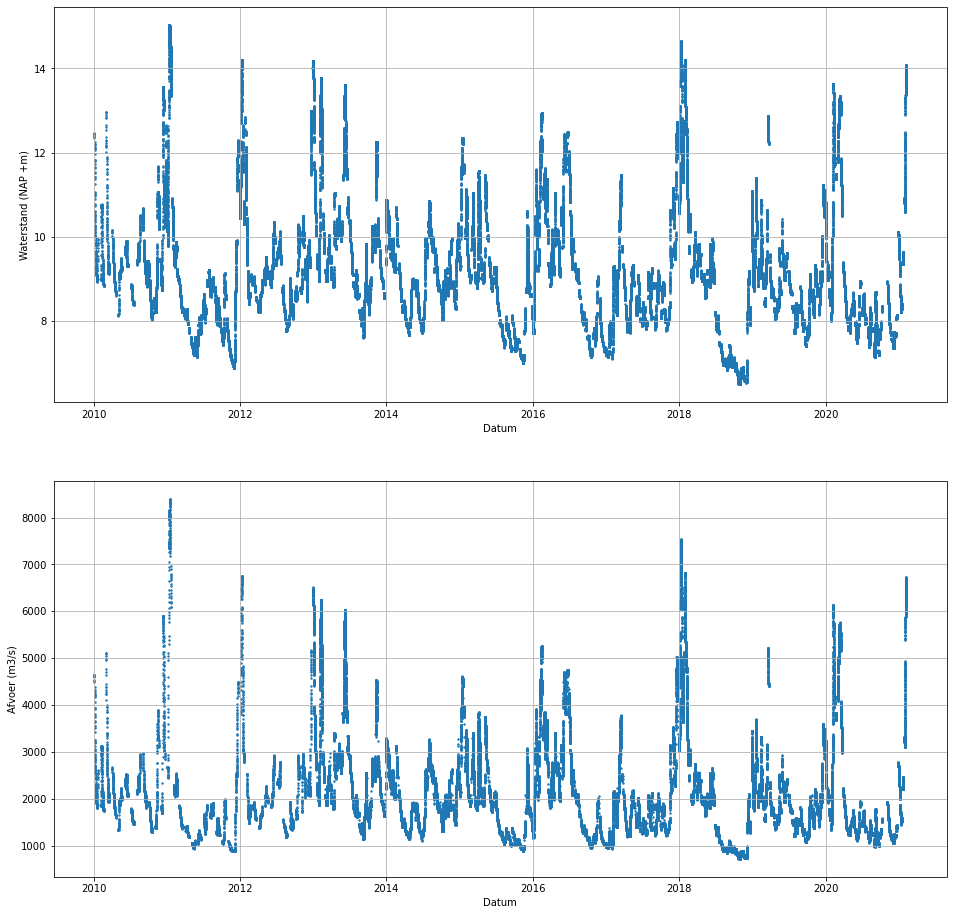
De Rijn voert gemiddeld 2.200 kubieke meter per seconde (m3/s) af, ofwel 2,2 miljoen liter per seconde. Over het jaar varieert het sterk. Voor de dijken langs de Rijntakken geldt 16.000 m3/s bij Lobith als uitgangspunt voor het ontwerp. Als het daaronder blijft dan hoeven we ons geen zorgen te maken. Hieronder staat de afvoer van de afgelopen maand.